



Este artigo tem dois objetivos principais: em primeiro lugar, fazer uma introdução, em linguagem acessível, sobre os Sistemas de Informações Geográficas (SIG, ou GIS em inglês), mostrando o que são, o que fazem e o que (e isso é muito importante) não fazem. Em segundo lugar, contribuir para difundir o seu uso para atividades de planejamento em geral, e de planejamento urbano em particular. Ainda que o leitor não saia imediatamente daqui para um curso de SIG ou para uma loja de softwares, se ele entender seu potencial e suas limitações e incentivar sua utilização dentro de seu órgão / departamento / instituição (ou pelo menos não criar obstáculos), este trabalho já terá mais que cumprido seu objetivo.
O que é SIG? O que ele faz?
Uma possível definição para o SIG seria a seguinte: SIG pode ser definido como um sistema implementado em computador que tem como função adquirir, armazenar, manipular, analisar e visualizar dados do mundo real sob três aspectos (1): a) dados geográficos, que são aqueles definidos espacialmente e representados normalmente através de mapas; b) suas características, ou atributos, normalmente compostos por valores alfanuméricos armazenados em forma de tabelas; e c) as relações espaciais entre os elementos, chamadas “relações topológicas”.
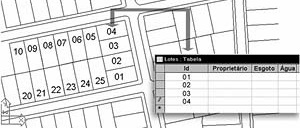
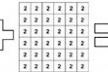
Em outras palavras, um SIG é um sistema, normalmente implementado em computador, que vincula elementos com representação espacial (por exemplo, lotes, ruas, edificações ou setores censitários) às suas características não espaciais (por exemplo, proprietário, tipo de pavimentação, tipo de uso ou renda média). Imagine que seu programa CAD estivesse ligado à sua planilha eletrônica, e que clicando em um elemento do primeiro fosse possível selecionar uma linha correspondente no segundo, contendo informações sobre o objeto selecionado. Em linhas gerais, é isso o que o SIG faz [figura 1].
Acontece que esse princípio simples abre um número praticamente infinito de possibilidades de utilização, limitado apenas pela criatividade e pelo conhecimento do operador do sistema, o que levou a uma grande popularidade desse tipo de sistema nos mais variados campos do conhecimento.
Maguire e Dangermond (3) classificam os procedimentos realizados pelos SIGs em:
a) Captura, importação, validação e edição – esse procedimento envolve as etapas necessárias à alimentação do sistema com os dados a serem manipulados. Estes podem ser adquiridos através da importação de dados já existentes em outros formatos ou podem ser confeccionados especificamente para introdução no sistema através de técnicas como sensoriamento remoto, restituição aerofotogramétrica, digitalização de levantamentos topográficos, etc. Entretanto, existem uma série de condições às quais esses dados devem obedecer, no que diz respeito à sua estrutura, para que possam ser utilizados. Por isso, eles precisam ser analisados, e eventuais incoerências e imperfeições devem ser corrigidas.
b) Armazenamento e estruturação – envolve o armazenamento dos dados de forma estruturada, de modo a possibilitar e facilitar a realização de análises. A forma como os dados são estruturados é crucial para o sistema, pois dela dependem os tipos de análises que poderão ser realizados.
c) Reestruturação, generalização e transformação – a reestruturação envolve a transformação das estruturas dos dados, muitas vezes de vector para raster e vice-versa (conforme será explicado mais adiante). A generalização refere-se aos processos de suavização de contornos e agregação de dados, quando se quer utilizar dados provenientes de escalas grandes (e portanto com alto nível de detalhes) em análises em escalas pequenas (nas quais esses detalhes não são importantes). A transformação envolve translação, rotação e escalonamento de dados geográficos, assim como operações matemáticas diversas nos atributos alfanuméricos contidos nas tabelas (como por exemplo o cálculo da densidade, dividindo-se o total de população de um polígono pela sua área).
d) Consulta e análise – Envolve as operações de: 1) Recuperação – operações básicas de seleção de informações baseadas em critérios espaciais ou não-espaciais. Assim, por exemplo, é possível selecionar todos os setores censitários situados a menos de 500m da orla marítima (critério espacial) e cuja renda média seja inferior a três salários mínimos (critério não espacial); 2) Sobreposições – funcionam a partir da sobreposição vertical de layers de informações, com o intuito de realizar operações entre eles. Esse procedimento será melhor discutido no item seguinte; 3) Vizinhança – avalia as características da área ao redor de uma localização específica; e 4) Conectividade – envolve principalmente análises de rede, tais como o cálculo do caminho mínimo entre duas ou mais localizações.
e) Apresentação – consiste na apresentação dos resultados, seja em forma de mapas, gráficos, tabelas, listas, resumos ou relatórios estatísticos. O grande diferencial dos SIGs, entretanto, são mesmo os mapas.
Então o SIG faz análises?
Não. Quem faz análises é o usuário, com o apoio do SIG. Isso pode parecer óbvio (e é), mas muitas vezes nos esquecemos desse fato, e acreditamos que simplesmente aprendendo a manipular um software de SIG estaremos aptos a realizar qualquer tipo de análise importante para a nossa tarefa. Isso não é verdade. A parte mais fácil é dominar o software; o difícil é saber o que fazer com os dados para que eles se transformem em informação com significado relevante para os objetivos do planejamento.
Por isso, é importante que saibamos exatamente o que estamos querendo analisar, para que o problema possa ser modelado adequadamente. Esse conceito de “modelar” é essencial para o uso dos SIGs. Para os propósitos deste artigo, modelar significa identificar os elementos da realidade relevantes para o que se quer analisar, bem como as relações entre eles, e representá-los de uma forma que possa ser manipulada pelo SIG.
Como seria de se esperar, dados espaciais e não espaciais têm requisitos diferenciados quanto à sua modelagem. Vamos então a eles.
Dados espaciais
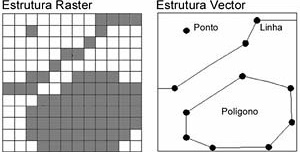
Os dados espaciais são representados, basicamente, por três tipos de elementos: ponto, linha e polígono. Eles devem estar separados em camadas de informação (ou layers), cada uma delas referente a um aspecto da realidade e composta por apenas um desses tipos.
Essas camadas de informação podem estar estruturadas de duas formas principais: estrutura raster ou estrutura vector, que condicionam diferentes maneiras de tratar os dados e diferentes possibilidades de manipulá-los para a realização de análises.
Estruturas Raster
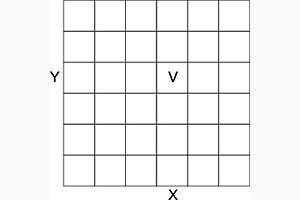
A estrutura raster é composta por uma matriz de pontos (ou células) com dimensões constantes, representando cada um uma porção quadrada de área [figura 2]. Sua localização é determinada pelas coordenadas geográficas do centróide da célula. Dessa forma, cada célula é definida por dois valores, representando as coordenadas x e y, e mais um terceiro, que representa um atributo não-espacial associado àquela localização no espaço. O tamanho da célula determina a resolução da camada de informação, e deve ser tanto menor quanto maior for a escala utilizada (ou seja, quanto maior a necessidade de detalhes, menor deve ser a dimensão da célula).
A estrutura raster é a mais indicada para representar elementos de variação contínua no espaço, tais como altitude, clima, níveis de poluição, etc. Portanto, todos aqueles aspectos cuja definição precisa dos limites dos elementos são difíceis ou inviáveis, tendem a ser melhor representados via uma estrutura raster. Por esse motivo, essa estrutura é muito utilizada em análises ambientais.
Uma das principais formas de análise com dados raster é a chamada álgebra de mapas. Elas funcionam segundo um princípio muito simples, mas poderoso: duas camadas contendo informações sobre uma mesma área podem ter seus valores combinados para gerar uma terceira camada, com novas informações relevantes para a análise. Essa “combinação” de duas camadas pode ser uma operação matemática ou operações lógicas do tipo AND, OR e NOT.
Vejamos um caso concreto: Gomes et al (4) procuravam o melhor traçado para uma rodovia. Para defini-lo, construíram uma “superfície de custo”, cujas células representavam a maior ou menor resistência de cada localização ao movimento. Para construir essa superfície foi utilizada a álgebra de mapas. O processo funcionou da seguinte maneira: para cada aspecto considerado relevante para determinar a resistência ao movimento (ou seja, o custo) foi criado um layer. Esses aspectos foram o relevo, a hidrografia, a litologia, a presença de núcleos urbanos e a presença de outras rodovias.
Para o relevo, por exemplo, o custo de cada célula foi calculado com base na diferença da sua altura original (obtida de um layer com as elevações) em relação ao perfil longitudinal do traçado. Esses custos, portanto, refletem o que seria gasto com cortes ou aterros para que a rodovia pudesse ser construída. Para os núcleos urbanos, os autores determinaram o critério de exclusão, ou seja, a presença deles automaticamente excluía a possibilidade de a rodovia passar por ali. Seguindo o mesmo princípio, foram criadas superfícies de custo para os demais aspectos, cada uma delas levando em consideração as conseqüências do aspecto no custo final de construção da rodovia.
A seguir, os layers de custo de cada aspecto foram somados, gerando um novo layer que sintetizava todos os custos. Essa soma funciona somando-se os valores de cada posição, isto é, na posição x, y do novo layer criado, será atribuído um valor correspondente à soma de todos os valores localizados na posição x, y de cada um dos layers utilizados no cálculo. Com isso, os autores chegaram a um layer que continha a somatória dos custos em cada célula, que no seu conjunto determinavam uma “superfície de custos”. A partir dessas superfície, foram utilizados alguns algoritmos de caminho mínimo oferecidos pelo SIG para definir o melhor traçado.
Reforçando o que foi dito acima, a operação de soma dos mapas é relativamente simples, comparada com a tarefa de modelar o problema, ou seja, determinar quais os aspectos que devem ser levados em consideração, como calculá-los, qual a importância relativa de cada um deles, etc. Esta última é, portanto, o conhecimento mais importante quando vamos realizar análises em SIG.
Estruturas Vector
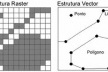
A estrutura vector também utiliza os três tipos de representação citados acima (ponto, linha e polígono), mas baseia-se em pares de coordenadas que se combinam para compor cada um desses tipos. Assim, um par de coordenadas define um ponto. Uma cadeia de pares de coordenadas define uma linha. E uma cadeia de pares de coordenadas onde o primeiro e o último são coincidentes define um polígono. Note que normalmente esse caráter de polígono “fechado” deve estar explícito, ou seja, não é suficiente que os pontos sejam coincidentes, o software precisa “saber” que eles compõem um polígono fechado. Essa é uma fonte permanente de trabalho de edição de dados provenientes de arquivos CAD; entretanto, ela pode ser facilmente superada se as providências corretas forem tomadas no momento de confecção dos elementos espaciais.
No caso da estrutura vector a vinculação aos atributos acontece por meio de um identificador (Id) atribuído a cada elemento vetorial. Esse Id corresponde ao campo-chave de uma tabela de atributos que contém outros campos (ou colunas). Assim, cada registro (ou linha) de uma tabela, contendo um identificador em um campo-chave, corresponde àquele elemento espacial que possui o mesmo Id [figura 3].
A estrutura vector é a mais indicada para lidar com elementos discretos, ou seja, que apresentam limites bem definidos, assim como nos casos em que são necessárias análises refinadas de topologia de redes.
A figura 4 ilustra os dois tipos de estruturas de dados.
Aplicações dos SIGs
Por ser uma ferramenta genérica, os SIGs são utilizados numa ampla gama de aplicações, com as mais diversas finalidades.
Um exemplo são os cadastros municipais de propriedades. Nesse tipo de aplicação, as principais funções se referem à busca e consulta de propriedades, recuperando informações sobre o proprietário, a legislação incidente (principalmente no que diz respeito à viabilidade construtiva), área construída e pagamento de impostos. Apesar desta última ainda ser considerada como a principal função dos cadastros (função de arrecadação), há algum tempo vem sendo reforçado seu potencial como instrumento de planejamento, impulsionado pelas funcionalidades oferecidas pelos SIGs que tornam possível a utilização dos dados cadastrais para análises urbanas.
Assim, dados desagregados como os contidos em cadastros imobiliários podem ser agrupados para a realização de análises com unidades espaciais maiores, como por exemplo os trechos de logradouros, os setores censitários ou os bairros. Da mesma forma, os dados podem ser categorizados para atender a objetivos específicos da análise, tais como a análise apenas de atividades comerciais, a localização de empregos e habitação, e assim por diante. Tudo isso com a vantagem de ser uma base de dados que está (teoricamente) sempre atualizada.
Com relação aos aspectos ambientais, por outro lado, as possibilidades de utilização dos SIGs também são grandes. Conforme já mencionamos, a estrutura raster se presta bem à representação de fenômenos de variação contínua no espaço, característicos dos estudos ambientais.
Dessa forma, cruzando informações de uso do solo, cobertura vegetal e hidrografia, por exemplo, pode-se ter um mapa de espaços mais adequados aos depósitos de lixo. Análises de buffer podem garantir o afastamento adequado dos cursos d’água, enquanto análises booleanas simples (pode / não pode) combinando as classificações de vegetação e uso do solo podem eliminar do universo de possibilidades aquelas áreas que sofreriam impacto negativo com a presença do lixo.
Existe também a possibilidade de incorporar valores numéricos às análises, tais como declividade, altitude ou índice pluviométrico. Na verdade, as possibilidades de cruzamentos e de realização de análises são praticamente infinitas, dependendo apenas da capacidade do analista de descrever fenômenos e relações de uma forma que estes possam ser representados nos SIGs.
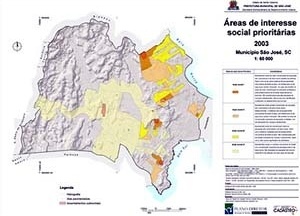
Karnaukhova et al (5) utilizaram amplamente o SIG no processo de elaboração do Plano Diretor de São José, principalmente nas etapas iniciais de análise e detecção de problemas, mas também na confecção dos mapas finais de zoneamento e das estratégias.
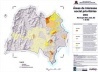
Dentre as várias análises realizadas, uma delas foi a delimitação das áreas de especial interesse social. Para isso, foram definidas e combinadas as áreas com maiores índices de concentração da população de baixa renda, população com baixos níveis de instrução e áreas com maiores índices de demanda por equipamentos comunitários (5). Essas áreas foram então classificadas em 4 tipos, de acordo com o nível de prioridade, e mapeadas [figura 5].
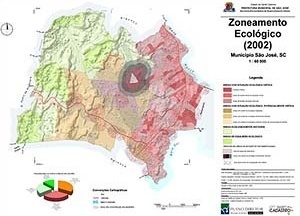
Outra análise de extrema relevância foi a determinação do zoneamento ecológico, que avaliava a diferenciação das diversas porções do território segundo seu estado e dinâmica ecológica, discriminando-as segundo a necessidade de ações específicas para o estabelecimento de programas de gestão e mitigação de impactos. Dessa forma, aspectos como a densidade populacional, fontes de poluição e indicadores de preservação ecológica das bacias hidrográficas foram combinados entre si para gerar o zoneamento, composto por 4 classes principais (situação ecológica crítica, potencialmente crítica, instáveis e ecologicamente equilibradas) [figura 6].
Considerações finais
A disseminação dos SIG por diversos setores da sociedade, e para as mais variadas finalidades, juntamente com a ênfase dada na sua capacidade inovadora de armazenamento, manipulação e visualização de dados espaciais e seus respectivos atributos, tem elevado os SIGs à categoria de grande ferramenta capaz de resolver a maioria dos problemas de planejamento. No entanto, isso tem mascarado algumas limitações que reduzem a aplicabilidade desse tipo de sistema em problemas de planejamento urbano.
Segundo Wegener (6), o SIG ainda não está completamente difundido pelos departamentos de planejamento e, mesmo onde ele está implementado, seu uso se restringe basicamente a atividades de mapeamento. Este argumento é defendido também por outros autores, entre eles Batty (7), Harris e Batty (8) e Sui (9).
Isso acontece porque as capacidades analíticas embutidas nos sistemas comerciais de informações geográficas são genéricas, e não se baseiam na lógica específica de funcionamento do sistema adotado como objeto de estudo (8). Dessa maneira, relações existentes no fenômeno urbano que não possam ser representadas através de análises de buffer, cálculo de distâncias, interseções, etc., (como a acessibilidade, por exemplo) não são facilmente realizadas pelos SIG.
Nesse sentido, os SIGs, da forma como vêm sendo utilizados atualmente, mostram-se inaptos a trabalhar com dados relativos a prognósticos (8), o que seria de grande utilidade para a prática do planejamento. Assim, análise de impactos imediatos podem ser realizadas, mas as conseqüências desses impactos nas outras variáveis do sistema, ao longo do tempo, não são facilmente avaliadas. Para superar essas limitações, é necessário integrar funcionalidades mais refinadas aos SIGs através de modelos urbanos. Para uma maior discussão das limitações dos SIGs e das potenciais vantagens em uni-los a modelos veja Saboya (2).
De qualquer forma, mesmo com essas limitações, os SIGs oferecem um enorme potencial para a realização de análises urbanas, potencial este que ainda está por ser explorado. Apesar de já estar relativamente difundido pelas administrações municipais, os sistemas ainda sofrem de males como desatualização, falta de coerência nos dados, incompletude, má estruturação, falta de pessoal capacitado e de procedimentos padronizados de manipulação, entre outros problemas. Enfim, temos um longo caminho pela frente que, apesar de promissor, nos trará muitos desafios.
notas
1
BURROUGH, P. Principles of Geographical Information Systems for land resources assessment. Oxford: Claredon Press, 1986.
2
SABOYA, Renato. Análises espaciais em planejamento urbano: novas tendências. Revista Brasileira de Estudos Urbanos e Regionais, v. 3, p. 61-79, 2000.
3
MAGUIRE, D; DANGERMOND, J. The functionality of GIS. In: MAGUIRE, D; GOODCHILD, M; RHIND, D. Geographical information systems: principles and applications. London: Longmans, 1991. p. 319-335.
4
GOMEZ, Montserrat et al. Diseño de carreteras mediante un sistema de información geográfica: costes de construcción y costes ambientales. Ciudad y Territorio Estudios Territoriales, v. III, n. 104, p. 361-376, 1995.
5
KARNAUKHOVA, Eugenia et al. Leitura da cidade de São José - SC (tendências e potenciais). Florianópolis: GT-Cadastro, 2004.
6
WEGENER, Michael. GIS and spatial planning. Environment and Planning B: Planning and Design, n. Anniversary Issue, p. 48 -52, 1998.
7
BATTY, Michael. Urban modeling in computer-graphic and geographic information system environments. Environment and Planning B: Planning and Design, v. 19, p. 663 -668, 1992.
8
HARRIS, Briton; BATTY, Michael. Locational models, geographic information, and planning support systems. National Center for Geographic Information and Analysis (NCGIA) 1992. Technical Paper 92-1. Disponível em: <http://www.ncgia.ucsb.edu/Publications/tech-reports/92/92-1.PDF>. Acesso em: 23-11-2004.
9
SUI, D. GIS-based urban modelling: practices, problems and prospects. International Journal of Geographical Information Science, v. 12, n. 7, p. 651 -671, 1998.
sobre o autor
Renato T. de Saboya é arquiteto e urbanista (UFSC), mestre em Planejamento Urbano e Regional pelo PROPUR – UFRGS, doutorando em Cadastro Técnico e Gestão Territorial – UFSC, professor do curso de Arquitetura e Urbanismo – UFSC